Data Buses
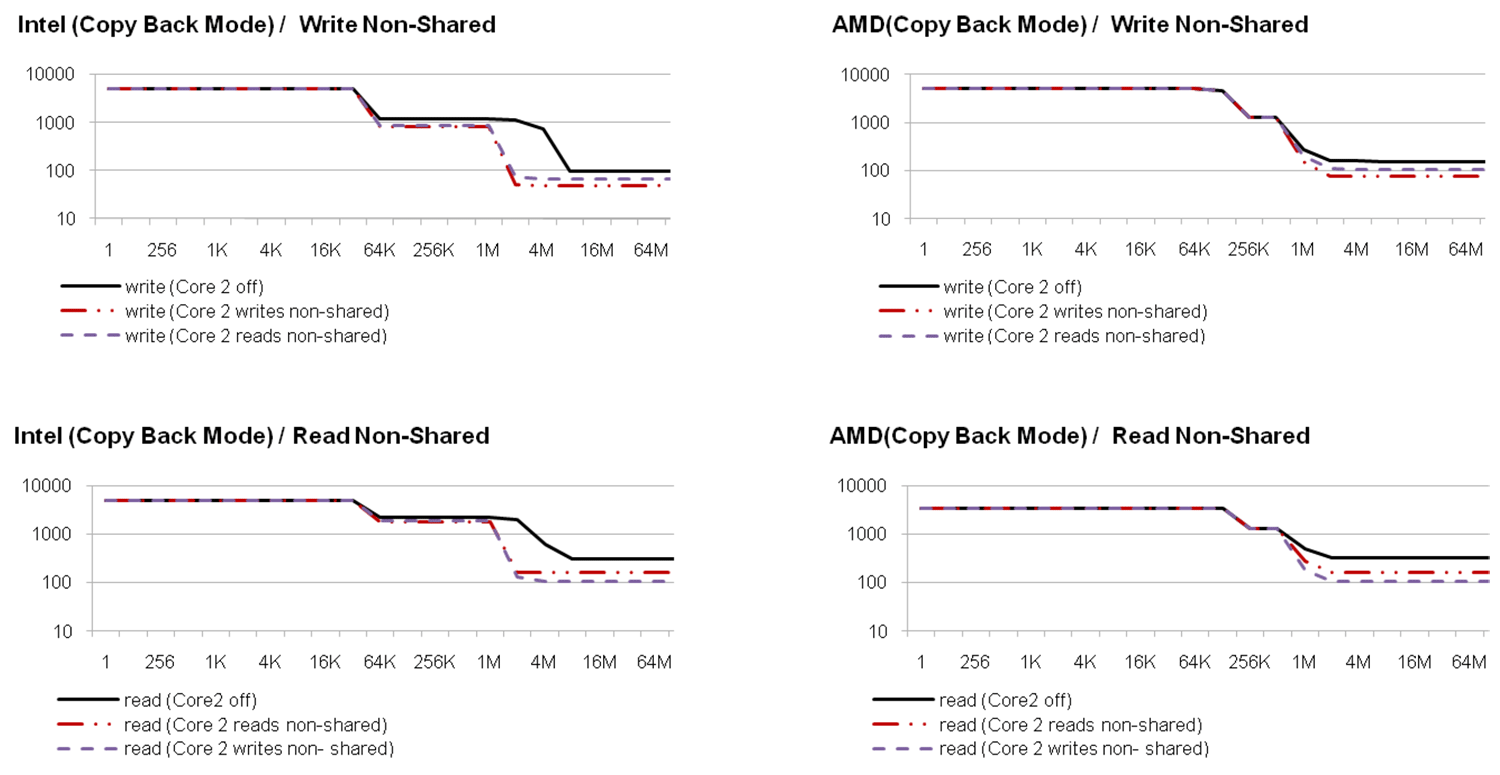
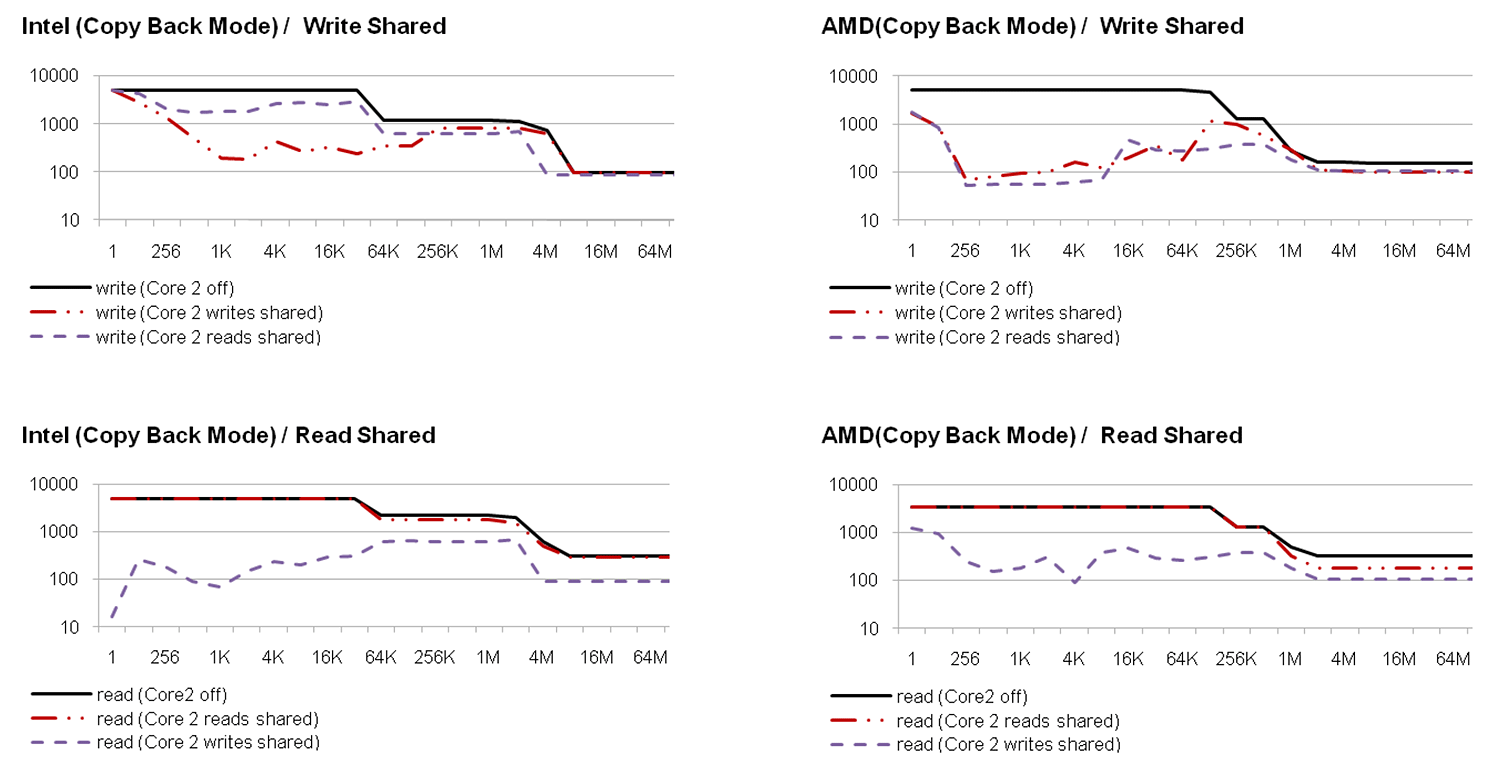
The results of the performance measurements (Figure 2 and 3) show that the bandwidth of the memory bus is shared between the cores. If the cores operate on a data set which is so large that the caches have no effect, the performance drops down to 50% if both cores are active. The same effect has been measured on the PCI bus. While a cache hit rate of 0% may be very unlikely when accessing memory, it is the normal case on the PCI bus since PCI devices are typically accessed with caches disabled.
Shared I/O Devices
The reduction of performance caused by concurrent access to a shared I/O device mainly depends on the bus which connects the device to the processor (e.g. the PCI bus) and on the device itself. A device which can only handle one request at a time may block a second request for hundreds of microseconds.
Shared Interrupts
On a multi-core platform, a hardware interrupt is typically routed to one core. If multiple devices are attached to one interrupt line and the devices are not served by the same core, the core who receives the interrupt must pass this interrupt also to the other core(s) forcing them to check the interrupt status of their devices. Shared interrupts may cause a significant interference between the cores and must be avoided by an appropriate platform design.
Software Interference Channels
One of the key components of an IMA module is the core software including the operating system. The core software must provide an execution environment for the hosted applications which on the one hand hides the platform characteristics from the hosted applications and on the other hand strictly controls the use of platform resources for all applications. While most hardware platforms and operating systems are designed for optimized average computing performance, IMA modules must distribute a high and constant level of computing bandwidth to applications according to the predefined time schedule. The system software must prevent unintended coupling between partitions due to access to shared resources and must not introduce additional interference channels due to concurrent access to the system software itself. Compared to a single core design, where asynchronous platform utilization with impact on the running application is mainly limited to interrupt processing and DMA transfers initiated by I/O devices, asynchronous access to platform and system software resources is the normal case on multi-core platforms.
The diversity of CPU and platform architectures and functional requirements leads to different concepts of multi-core support in the core software component. For a dual-core CPU an adapted ARINC 653 time partitioning concept might be appropriate while for a CPU with 32 or more cores, time partitioning might no longer make sense. In the following we assume a system software design which is compatible with the ARINC 653 partitioning concept but we assume, that specific partitions may need to utilize multiple cores.
Software Concepts for Multi-Core Platforms
Interference between software components running concurrently on different cores mainly depends on the software architecture and the way the software utilizes the cores. The following sections discuss the different concepts of using multi-core processors and the related interference issues.
Operating System Level
On operating system level, two concepts for utilizing multiple processor cores are distinguished:
The Asymmetric Multiprocessing (AMP or ASMP) and the Symmetric Multiprocessing (SMP).
The AMP approach utilizes a multi-core processor platform very much like a multi-processor system. Each core runs its own single-core aware system software layer. The cores are loosely coupled through distinct communication channels which may be based on inter processor interrupts, specific shared memory regions or other external devices.
The major advantages of the AMP approach are:
- The system software layer does not need to be multi-core aware which simplifies the design.
- There is no implicit coupling through shared data and critical sections inside the system software layer.
- Each core may run a system software layer which is optimized for the task to be performed. An example for this is a dual-core platform where one core is responsible for I/O processing and data concentration while the other core runs an ARINC 653 compliant OS which hosts the applications.
The disadvantages of the AMP approach are:
- All system software instances must be certified to the highest level applicable for the platform since they have full access to privileged processor registers and instructions.
- Partitioning of platform resources is more complicated, especially if different system software layers are used. This limits the use of the APM concept to CPUs with a small number of cores.
- Synchronization between applications running on different cores is more complex.
- The AMP approach does not support parallel execution on application level.
Interference on an AMP platform is mainly caused by shared caches, memory and I/O buses and concurrent access to shared devices. Interference on the memory bus is hard to avoid while access to I/O devices may be limited to one core. Coherency problems are limited to distinct communication buffers and interference caused by the system software is limited to shared device handles.
The SMP approach uses one system software instance to control all cores and platform resources. The OS typically provides inter and intra partition communication services which transparently manage cross core communication. Device drivers are responsible to manage concurrent access to platform resources.
The advantages of the SMP approach are:
- There is only one system software instance responsible for the partitioning concept which limits the certification effort to one software package.
- There is only one platform configuration layer required.
- The SMP system software can completely isolate execution of critical tasks, e.g. by temporary disabling concurrent execution of non-trusted partitions.
- SMP provides much more flexibility and allows a better load balancing than an AMP configuration.
- Parallel execution on application level can be supported where interference between cores is of no concern, e.g. for non-safety related partitions.
The main disadvantages of the SMP approach are:
- The system software layer is more complex since it needs to protect its internal data from concurrent access without significant impact on parallel service requests.
- The internal data need to be arranged very carefully in order to avoid false sharing effects.
- Due to the shared system software layer, an implicit coupling of unrelated execution threads cannot be completely avoided.
Compared to an AMP configuration the SMP approach adds an important source of potential interference which is the shared system software layer. A careful design however can limit the impact by the implementation of fine-grain critical sections. The internal data of the system software layer must be carefully arranged to avoid unintended coupling due to false sharing.
Parallel Execution on Thread Level
Parallel execution on thread level means that the programmer divides an application into multiple threads of execution and binds these threads to a processor core. The threads typically operate on the same data, e.g.. the applications data, bss and heap segments. All effects discussed with shared caches, cache coherency (especially false sharing) and bus sharing have to be addressed in order to determine the worst case performance of such an application. Due to the explicit thread creation the programmer has a more control over concurrent access to shared resources than in the case of parallel execution on block level using the OpenMP approach. Interference between threads of the same partition may cause timing problems for the application itself but it does not by itself impact partitioning.
Parallel Execution on Instruction Level
Certain portions of one logical execution thread may be executed in parallel by multiple processor cores if the processed input and output data are independent. The OpenMP Application Program Interface [5] defines compiler directives which indicate sections of code which may be executed in parallel. The OpenMP implementation uses the fork/join concept where the main thread forks a specified number of worker threads to execute the code section marked as parallel. After the parallel block is completed, the worker threads join back into the main thread. The allocation of the code instructions to the worker threads is done by the compiler. The interference considerations are the same as for parallel execution on thread level, but the risk of false sharing may even be higher due to the reduced data sets on block level.
An SMP Approach for IMA
In the previous sections we discussed different concepts for using multi-core processors. The AMP approach is interesting for specialized solutions, especially if used on a dual core platform where one core is completely dedicated to I/O processing and the other core runs the application software. The interference caused by the I/O processor is manageable since it runs completely under control of the (trusted) platform level software. This approach seems to be reasonable as a first step towards multi-core IMA but it does not provide a significant amount of additional processing bandwidth for the applications.
A more generic approach is the use of an SMP operating system since it scales better with an increasing number of CPU cores and it provides an increased flexibility.
We assume that future IMA platform have to host, besides the critical applications, an increasing number applications with high performance requirements but lower criticality. These applications may also not necessarily be based on the ARINC 653 intra-partition API, they may require run-time environments like POSIX®, Java or even Linux. They also may require multi-processing at application level.
Due to the potential interference between applications it seems not to be feasible to run a safety critical application concurrently with an non-trusted application. The operating system must support exclusive access to the platform for the most critical applications. Intra partition multiprocessing for safety critical applications also seems to be questionable because the worst case execution time analysis may become impossible.
When no critical application is running, the platform may be shared between partitions or all cores may be made available to the most demanding application.
The operating system PikeOS is a good example that shows that the need high performance computing for less critical applications and a high level of determinism and isolation for highly critical applications can be realized on a multi-core platform.
PikeOS provides an ARINC 653 compliant partitioning model which allows in addition to the ARINC 653 API to execute different run-time environments and APIs like POSIX®, ADA, Java or even a fully virtualized Linux inside a partition.
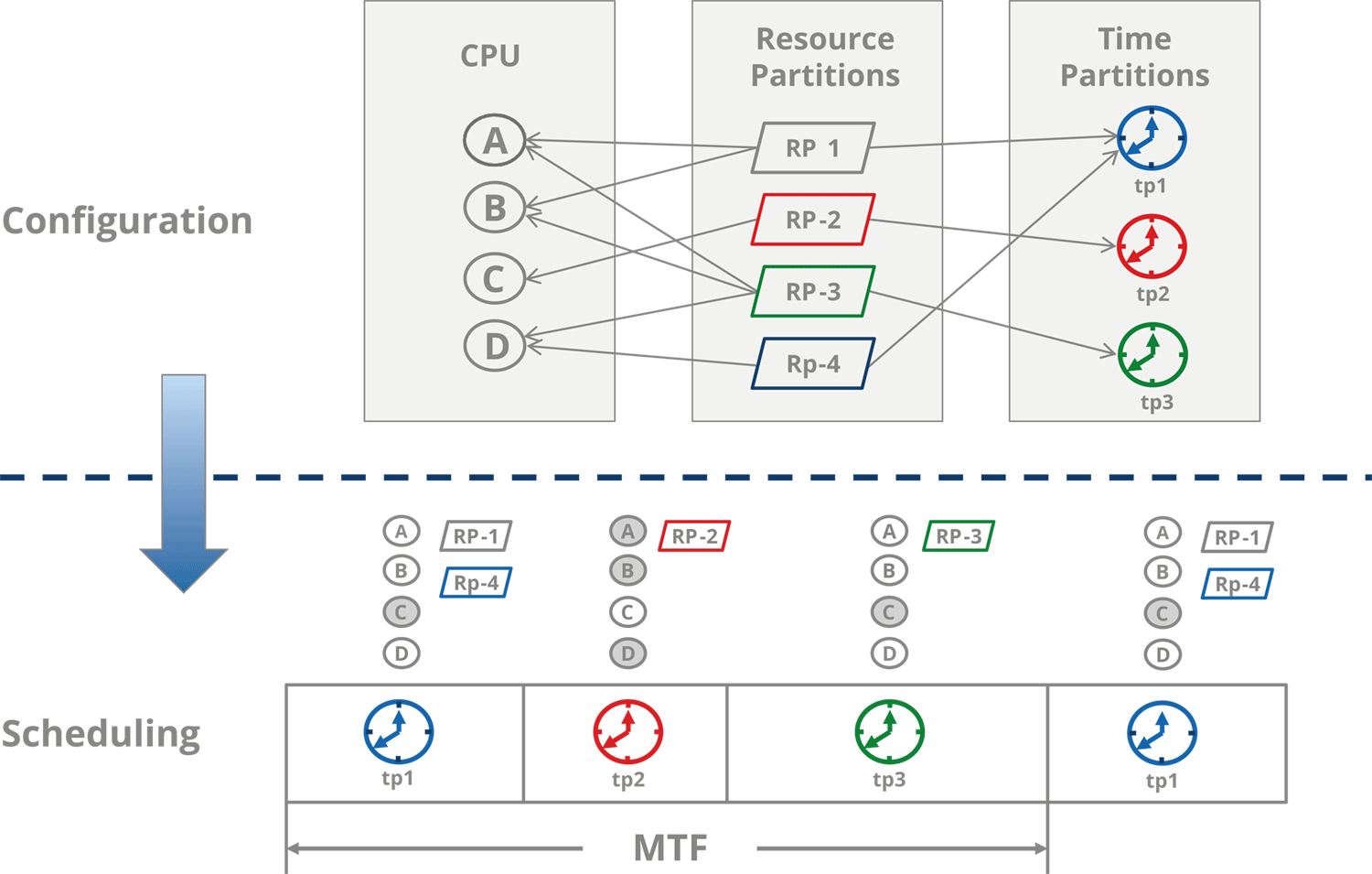
The scheduler executes a common Major Time Frame (MAF) which keeps the OS fully ARINC 653 compliant. CPU cores are statically assigned to resource partitions where one resource partition may utilize multiple cores. Figure 5 shows a possible configuration of the PikeOS partition scheduler:



 Twitter
Twitter LinkedIn
LinkedIn Facebook
Facebook Pocket
Pocket RSS
RSS